
Post-development sentiment and statistical analysis of different groups of psychiatric medications


Abstract
Background: medications are complex and influence the body in multiple ways. Post-development analysis of medications remains highly advantageous, as it allows for comprehensive understanding of the safety profile over extended periods and can direct future improvements to enhance the therapeutic benefits while minimizing risks. Our primary goal was to examine whether a substantial relationship exists between such patient experiences and the statistical analysis of data about the same medications from clinical trials.
Methods: Patient feedback regarding medication commonly prescribed for psychiatric conditions was obtained from a publicly available website webmd.com. We searched clinicaltrials.gov for statistical analysis regarding the same medications. Data from webmd.com was subjected to sentiment analysis, while clinicaltrails.gov data underwent statistical analysis.
Results: the findings suggest a general connection between the two data sources. Medications with a greater amount of patient feedback generally attract more research attention, although with some exceptions. Additionally, medications approved for children receive less feedback online compared to those for adults and seniors. Medications for seniors receive more positive and neutral feedback in contrast to those for children and adults.
Conclusions: online platforms offer a space for patients to share their experiences with using specific medications, potentially contributing to the enhancement of patient care and aiding researchers in further studies.
Citation
Toosi F G, Toussi A G. Post-development sentiment and statistical analysis of different groups of psychiatric medications. Eur J Transl Clin Med. 2024;7(1):47-56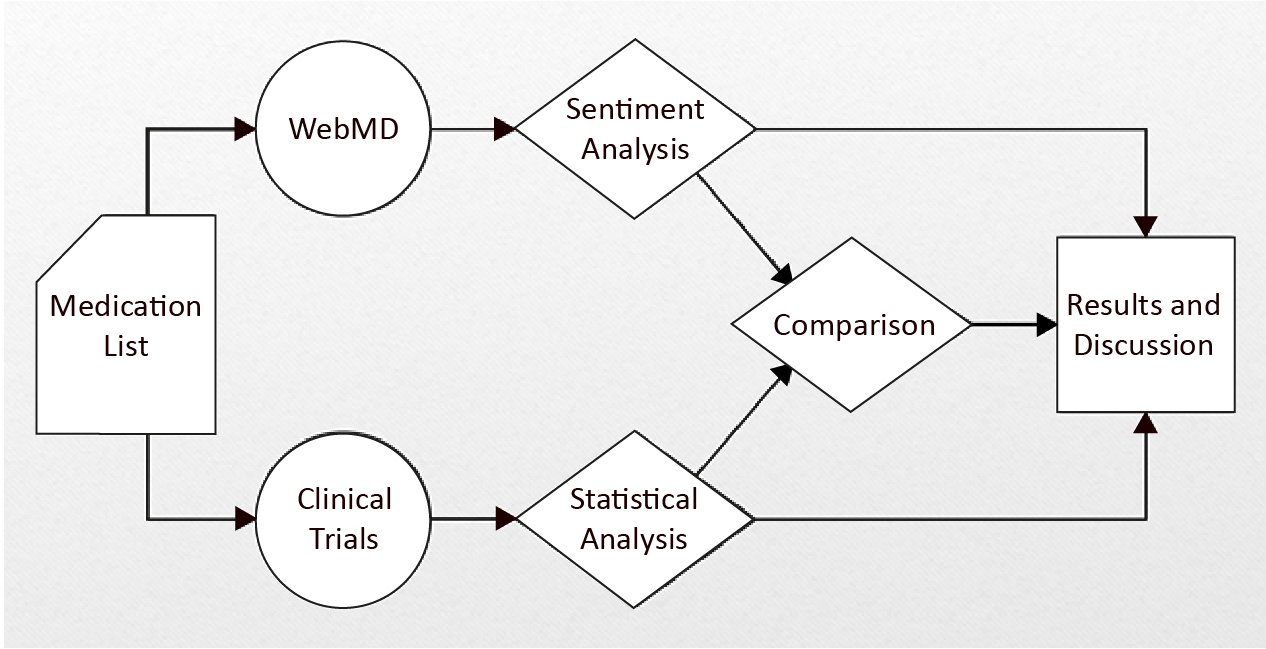







Introduction
The process of developing a new medication is complex and involves multiple steps e.g. pharmacology research, preclinical studies on animals, clinical studies on small groups of human volunteers, regulatory agency approval, marketing and more [1]. Medications may have various long-term adverse effects and drug interactions, which may require significant observation time to reveal. Post-development analysis of medications, including a series of analytical techniques, may be employed to reveal more details on different aspects of long-term adverse effects.
In general, there are two different approaches to examining the long-term effects of medications. The first approach involves collecting patient feedback. Online platforms allow patients to express their opinions about the medications they use. Since this feedback is provided by non-experts, it often lacks technical terms but instead conveys different feelings and sentiments. Patients might express dissatisfaction or satisfaction with a specific medication. Consequently, computer science techniques such as natural language processing (NLP), particularly sentiment analysis, can be employed to analyze these feedback data and provide a collective overview for a given medication [2]. The second approach involves conducting independent research trials related to the particular medication.
Healthcare-related websites, such as webmd.com, frequently showcase patient feedback, which can be valuable resources for individuals seeking information and support concerning medications [3]. Patient reviews/feedback, particularly for psychiatric medications, offer significant insights into the effects of these medications, revealing aspects that might not have been evident during the initial stages of drug development. These reviews provide information on a medication’s effectiveness, adverse effects, dosage, onset and duration of action, tolerability and comparisons to other medications.
The clinicaltrials.gov website serves as a repository encompassing both privately and publicly funded clinical studies conducted in various countries around the world. The details of these studies (e.g. conditions, number of participants and their demographic characteristics, intervention, outcomes) are inputted into the database manually. Users can search this repository for trials associated with specific medical conditions or medications. For instance, in our previous study analyzed the adverse effects of oxycodone by extracting data from all the clinical trials registered at clinicaltrials.gov [4].
Sentiment analysis [5], also known as opinion mining, is a natural language processing (NLP) technique that involves using machine learning models to determine the sentiment or emotional tone expressed in a piece of text, typically written or spoken language. Its primary goal is to classify text as positive, negative, or neutral based on the underlying emotions or opinions expressed.
Our primary aim was to examine whether there is a correlation between the patient experiences (assessed via sentimental analysis) with using medication commonly prescribed for psychiatric conditions and the statistical analysis of data about the same medications from clinical trials [6-12].
Material and methods
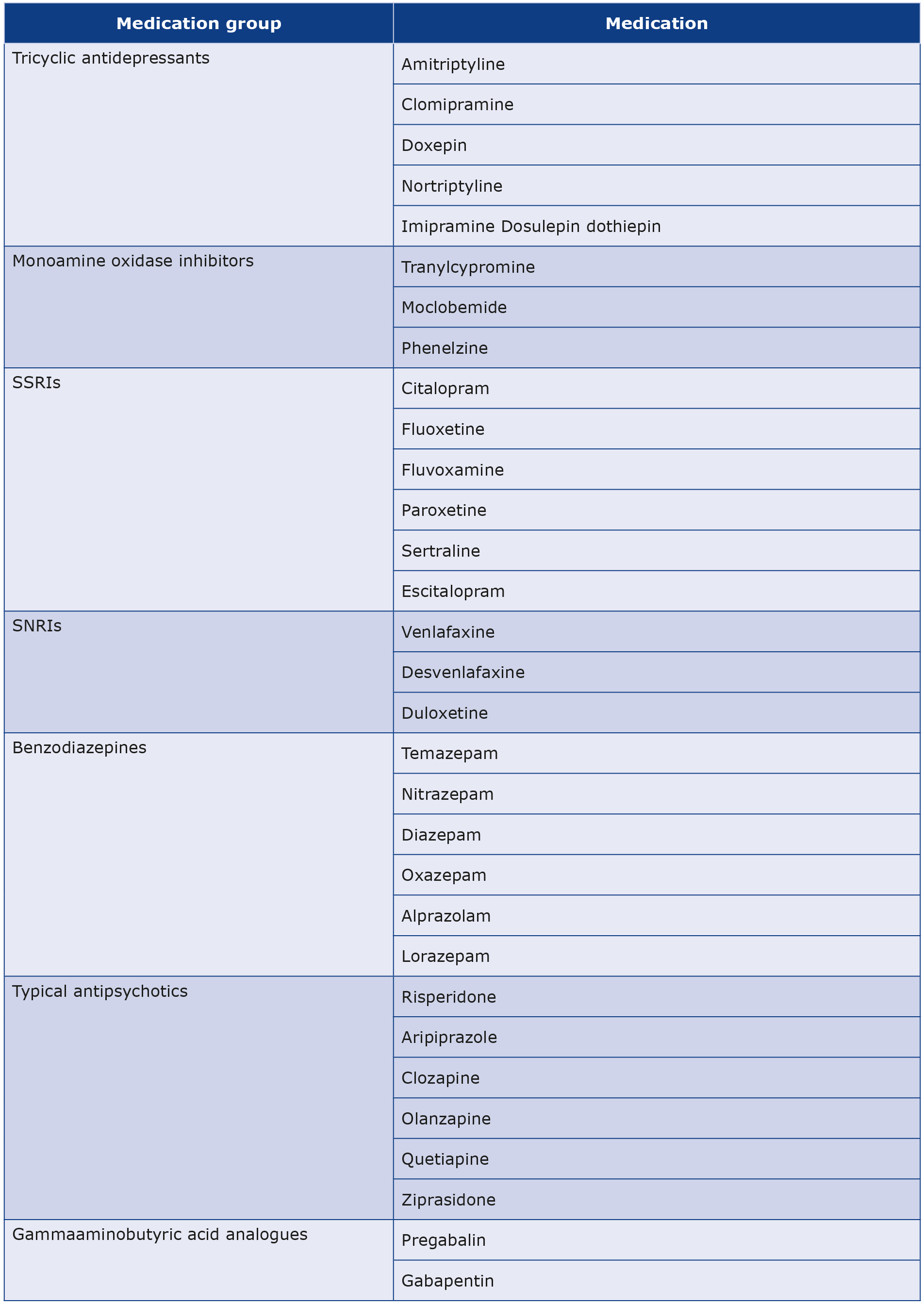
A variety of chemical and natural medications can be used to treat depression and anxiety [13]. We used a list of medications categorised by Constable et al. into seven groups based on their chemical structure and mode of action (see Table 1) [14].
Table 1. List of a number of psychiatric medications categorized in their groups
We collected from webmd.com all reviews and feedback for each medication listed in Table 1 and conducted a sentiment analysis on each specific review/piece of feedback. Specifically, we wrote a script in the Python programming language (version 3.10, Python Software Foundation, Delaware, USA) to extract information from web pages and organize it in a structured format. Then, we used the valence aware dictionary and sentiment reasoner (VADER), a rule-based sentiment analysis tool developed by Hutto et al. [9]. It assessed the medication review/feedback text and assigned polarity labels (ranging from -1 (most negative) to +1 (most positive)) and calculated a compound score that represents th overall sentiment (see Figure 1).
Figure 1. The entire process of this study
In addition to webmd.com, we also searched the clinicaltrials.gov repository for studies involving the same medication and extracted the following details: the number of studies, the number of participants in each study, age and gender of participants (categorized as child, adult, senior). This data was collected manually in a .csv file that was generated by the clinicaltrials.gov. After extracting the data for each chosen medication from both sources, we wrote the following research questions:
- Question 1. Which medications generally receive more positive and negative feedback from patients, and is there a discernible pattern among them in relation to their medication groups?
- Question 2. Which medications generally receive more attention from researchers, and is there a pattern related to their medication groups?
- Question 3. Is there a meaningful relationship between patients’ feedback on a given medication and the number of clinical trials for the same medication?
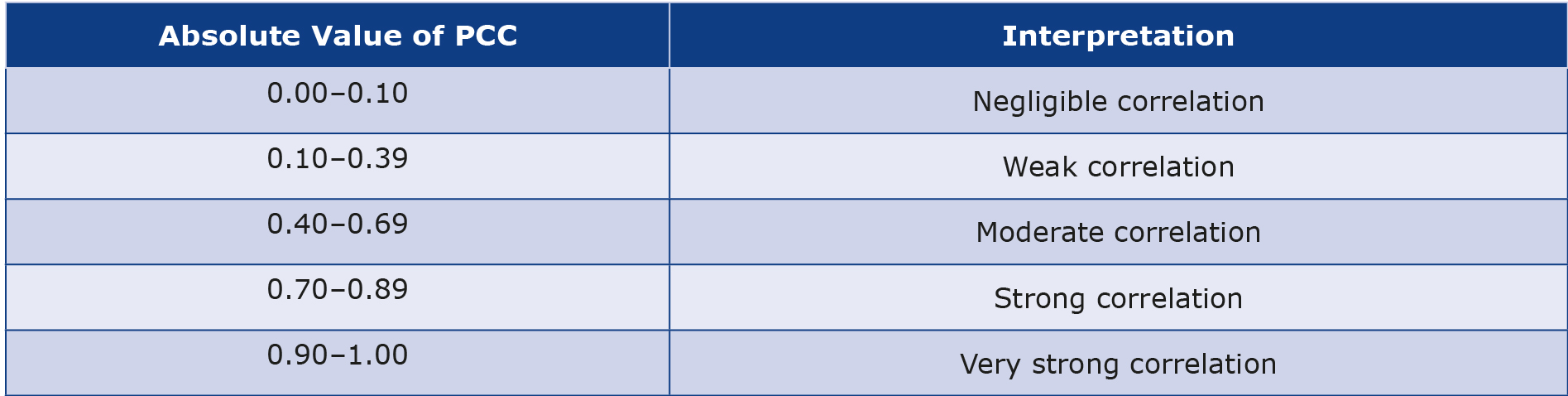
We explored the pairwise relations between the features of the webmd.com dataset and the features of the clinicaltrials.gov dataset. The p-value and Pearson correlation coefficient (PCC) were utilized to evaluate these interdependencies. Schober et al. detailed the correlation coefficient in their work which is regarded as a conventional method for interpreting the PCC [15]. We quoted the information their work in our Table 3 and used it as a reference for interpretation. In this study, we used the Pearsonr from the Scipy module (a Python application programming interface). In addition to the PCC (r), the Pearsonr function also calculates the p-value. The p-value is employed to assess the rejection of the null hypothesis (H0), which states that there is no relationship between two distributions of values. A p-value < 0.05 is commonly accepted as evidence to reject the null hypothesis, indicating the possibility of a linear relationship between the two distributions. All the analyses, including the sentiment analysis via VADER, were performed using Python code developed by the Authors. All the employed data and code can be found at github.com/farshad1982/Clinical-WebMD.
Results
Our analysis indicates that citalopram, escitalopram, risperidone, gabapentin, pregabalin, olanzapine, quetiapine, aripiprazole, duloxetine, sertraline and fluoxetine, were each included in > 300 clinical trials. However, the list of medications with the highest number of clinical trial participants is different: clozapine, duloxetine, venlafaxine, citalopram, escitalopram, fluoxetine, sertraline, paroxetine, desvenlafaxine, quetiapine and fluvoxamine, each having more than 4 million participants in total.
Medications with the highest number of female participants are: gabapentin, duloxetine, pregabalin, citalopram, escitalopram, fluoxetine, diazepam and sertraline. Medications with the highest focus on male participants are: citalopram, escitalopram, pregabalin, gabapentin, olanzapine, paroxetine, fluoxetine and aripiprazole.
We also identified medications with the highest focus on children, e.g. risperidone, aripiprazole, fluoxetine, gabapentin, olanzapine and sertraline. Medications with the highest focus on seniors are citalopram, escitalopram, pregabalin and gabapentin.
Additionally, we noted 4 medications that have not received a single review on webmd.com but were included in a few clinical trials: dosulepin and dothiepin (2 clinical trials each) and moclobemide, nitrazepam (14 and 17 trials respectively).
After analyzing our results, we answered our previously-mentioned 3 research questions.
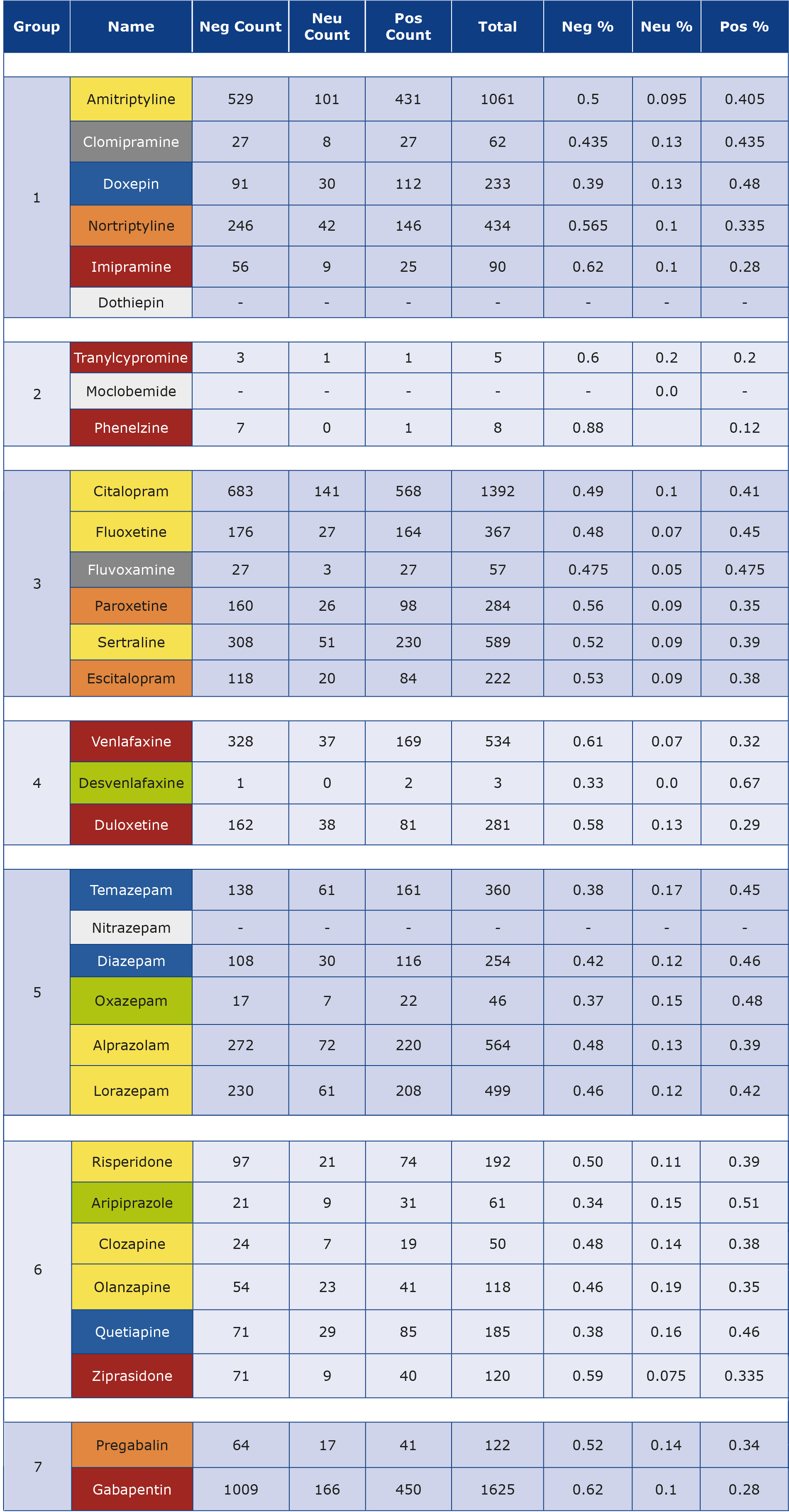
Question 1. Table 2 displays various medications, each color-coded to indicate the overall sentiment associated with them. Red signifies high negativity (i.e. large gap between negative and positive), orange represents medium negativity (i.e. medium gap between negative and positive), yellow indicates low negativity (i.e. low gap between negative and positive), gray illustrates an equal sentiment between positive and negative (i.e., no gap between negative and positive), blue denotes low positivity (i.e. low gap between positive and positive) and green reflects high positivity (i.e. large gap between positive and positive). Within the SSRI group, there are no medications with an overall positive sentiment. However, the Benzodiazepine group appears to have three medications with an overall positive sentiment and two with low negativity. GABA analogues generally display high or medium levels of negativity. Benzodiazepines in general, show the highest positive feedback, while MAO inhibitors, GABA analogues and SSRIs received the highest overall negative feedback. Other medication groups received a mix of positive and negative feedback.
Table 2. The details of sentiment analysis from the data collected from webmd.com.
Group 1: Tricyclic antidepressants, Group 2: Monoamine oxidase inhibitors, Group 3 represents SSRIs, Group 4: SNRIs, Group: Benzodiazepines, Group 6: Typical antipsychotics, Group 7: Gammaaminobutyric acid analogues
Table 3. Interpretation of PCC
Question 2. Table 4 presents the targeted medications categorized by their respective groups, with each medication color-coded based on the number of trials conducted. For instance, dark-green signifies a high number of trials, yellow represents a medium count, while light-red and dark-red indicate low number and very low attention, respectively. In general, GABA analogues were included in the highest number of trials, followed by the typical antipsychotics. SSRI medications were also relatively often included in trials. Conversely, TCA antidepressants and MAO inhibitors were not as extensively researched in clinical trials compared to other groups. Hence, the answer to this research question is ”yes,” indicating a meaningful relationship between the medication groups and the number of clinical trials.
Table 4. The details of statistical analysis from the data collected from clinicaltrials.gov.
Group 1: Tricyclic antidepressants, Group 2: Monoamine oxidase inhibitors, Group 3: SSRIs, Group 4: SNRIs, Group 5: Benzodiazepines, Group 6: Typical antipsychotics, Group 7: Gammaaminobutyric acid analogues
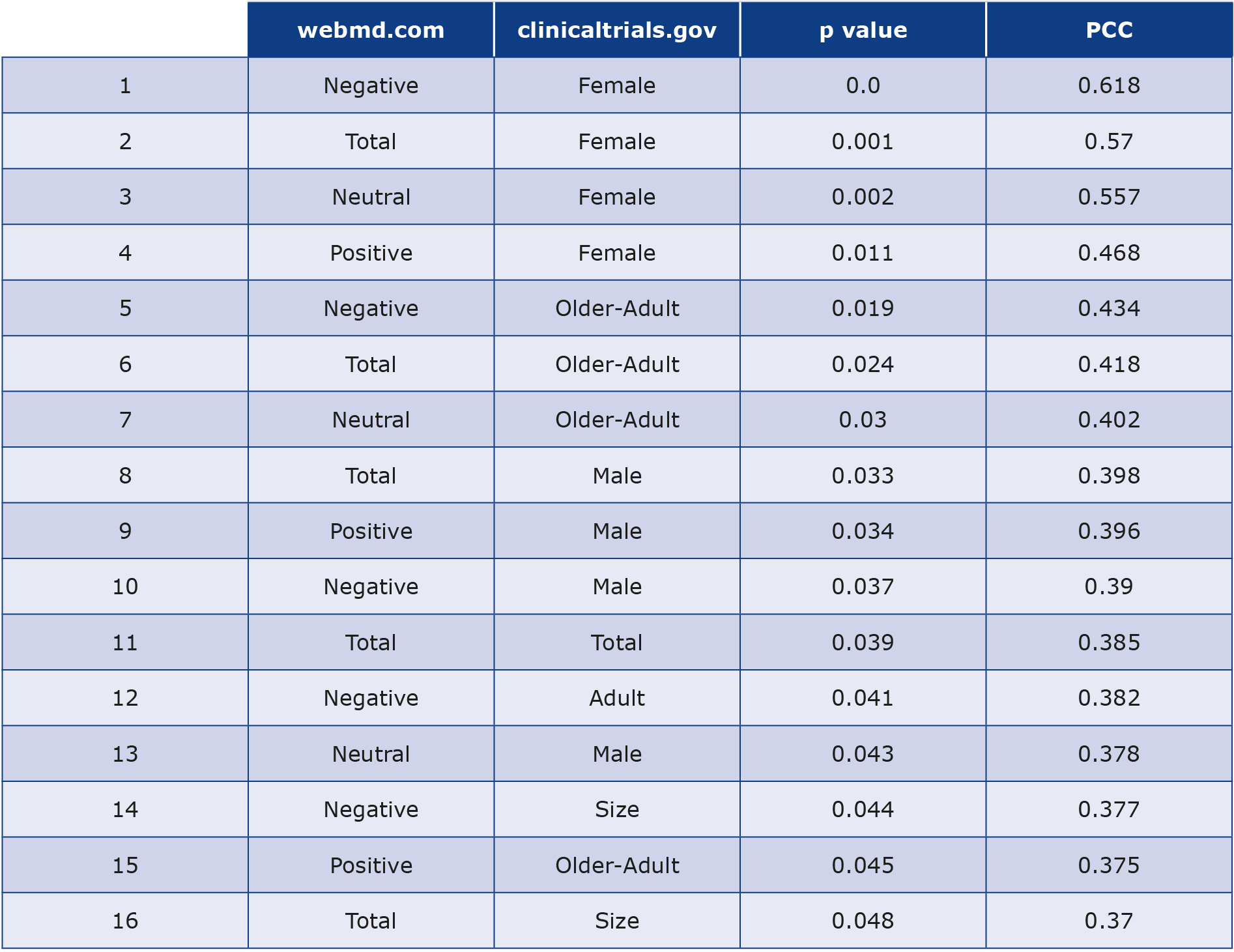
Question 3. Table 5 displays the existing correlations between the features from clinicaltrials.gov and the features from webmd.com. The following presents the notable correlations among these two datasets:
(a) clinicaltrials.gov focused on females exhibit the highest PCC (moderate correlation) and the lowest p-values with various types of feedback, including total feedback, from webmd.com. This implies that an increase in the number of negative feedback correlates with a rise in the number of trials focusing on female participants, and vice versa. particularly negative feedback, as indicated by the highest PCC and the lowest p-value.
(b) clinicaltrials.gov centered around on seniors also reveal moderate correlations with higher volume of feedback from webmd.com. Specifically, negative feedback increases with the rise in clinical trials involving seniors.
(c) clinicaltrials.gov focused on males tend to exhibit only weak correlations with various types of feedback from webmd.com,
(d) clinicaltrials.gov focused on adults also display a weak correlation, only with the negative feedback. This observation may suggest that adults contribute more to providing negative feedback exclusively. This pattern contrasts with the seniors, who contribute to positive and neutral feedback as well.
(e) There is no correlation between the trials involving children and the feedback posted on webmd.com.
Table 5. Statistical analysis of data about medication collected from webmd.com and clinicaltrials.gov
The upper part of Table 5 displays pairs of features (one from webmd.com and the second from clinicaltrials.gov) with p-values < 0.05 and a PCC > 40% (indicating moderate correlation), while the lower part shows pairs with p-values < 0.05 and a PCC between 30%-40% (indicating weak correlation).
Discussion
Conducting two sets of analyses on the same set of medications provides insight into how patient feedback might influence research studies. Two notable medications are citalopram and gabapentin. Citalopram is a primary focus for researchers due to the number of trials and one of the most reviewed medications on webmd.com. One of the main reasons for prescribing Citalopram is its perceived safety [16]. Gabapentin, having the highest number of reviews on webmd.com, also has a relatively high number of clinical trials. This could be due to the multi-functionality of gabapentin in the treatment of seizures, neuropathic and chronic pain, restless leg syndrome, migraines, anxiety disorder, hot flashes and certain mood disorders [17-18].
Additionally, medications aimed at children receive less online feedback compared to those for adults. Medications targeting older adults receive more positive and neutral feedback in contrast to those targeting children and adults. This trend may be attributed to the higher prevalence of chronic conditions among older adults, leading to more sustained use and thus more opportunities for feedback. Conversely, medications for children might have fewer feedback instances due to lower usage frequency or parental concerns about sharing information online. Furthermore, the higher positive and neutral feedback for medications targeting older adults could be influenced by their effectiveness in managing chronic conditions that significantly impact quality of life. These medications might also benefit from more robust clinical trials and post-market surveillance, contributing to better patient outcomes and satisfaction. It is also possible that older adults, or their caregivers, are more diligent in reporting their experiences with medications due to a more consistent interaction with healthcare providers. Additionally, the marketing strategies for medications targeting different age groups could play a role, influencing both the perception and feedback frequency. Finally, social and cultural factors, such as stigma or acceptance of medication use in various age groups, could also affect the nature and volume of feedback received.
Our data also suggests a correlation between the number of negative feedback instances and the increase in clinical trials focusing on female participants. This trend highlights the importance of addressing adverse reactions reported by females and underscores the need for gender-specific research in clinical trials.
There are other several tools other than VADER designed for sentiment analysis, e.g. the DistilBertForSequenceClassification, a pre-trained transformed-based model which is a variant of the original BERT (Bidirectional Encoder Representations from Transformers) [19-20]. However, we decided not to use the DistilBert model due to its limitations, e.g. insufficient data to train the model, complex fine-tuning requirements and a dependency on specific task types, leading to reduced generalization. Given the absence of training data in our work, machine learning tools such as DistilBert were not likely to be useful. In contrast, VADER functions based on a set of pre-defined rules (a lexicon) to interpret a text’s sentiment (emotional content, also termed as „valence”), considering word intensity, punctuation, capitalization and other linguistic features. For instance, VADER is accurate enough to recognize the negative sentiment in phrases such as ”I am not happy,” despite the presence of the word ’happy.’ Additionally, VADER can identify emoticons often used in informal language that is often found in user-provided reviews or feedback comments.
Limitations of our study
Our work utilized data available from an openly accessible forum created by patients. Although this platform allows patients from any location, ethnicity, and condition to report their experiences, there is still a risk of biased feedback for various reasons, which can potentially impact the final results. Detecting biased feedback is fundamentally challenging as this platform does not reveal the identity of the patient or confirm whether the patient has used the medication (non-biased) or not (biased). Our work employed an automated sentiment analysis technique (Vader), which is a rule-based method. Similar to AI-based techniques, there is a possibility for feedback to be sentimentally misinterpreted, often due to the grammatical structure of the feedback, such as the use of slang, colloquialisms or even non-English terms.
Conclusions
To the best of our knowledge, there is very little literature investigating the link between clinical trials and patient feedback about medications. Our findings suggest a general connection between the registered clinical trials and the feedback posted on webmd.com about the same medication. Clinical trials focusing on females and trials focusing on seniors were correlated with one or more type of feedback posted on webmd.com. Medications with a higher number of feedback generally attract more attention of researchers, although there are some exceptions. By integrating feedback from platforms like webmd.com with data from clinicaltrials.gov, researchers can better understand and respond to the unique medical needs of female patients, ultimately leading to more effective and inclusive healthcare solutions.
Conflict of interest
None.
Funding
None.
References
| 1. |
Lipsky MS, Sharp LK. From idea to market: the drug approval process. J Am Board Fam Pract [Internet]. 2001;14(5):362–7. Available from: https://www.jabfm.org/content/14/5/362.short.
|
| 2. |
Zunic A, Corcoran P, Spasic I. Sentiment Analysis in Health and Well-Being: Systematic Review. JMIR Med Informatics [Internet]. 2020;8(1):e16023. Available from: https://medinform.jmir.org/2020/1/e16023.
|
| 3. |
WebMD [Internet]. [cited 2023 Sep 27]. Available from: https://www.webmd.com.
|
| 4. |
Ghassemi Toussi A, Ghassemi Toosi F. A quantitative analytical investigation on the oxycodone side effects among the recent clinical trials. Eur J Transl Clin Med [Internet]. 2023;6(1):58–63. Available from: https://ejtcm.gumed.edu.pl/articles/163415.
|
| 5. |
Ahmet A, Abdullah T. Recent Trends and Advances in Deep Learning-Based Sentiment Analysis. In: Agarwal B, Nayak R, Mittal N, Patnaik S, editors. Deep Learning-Based Approaches for Sentiment Analysis Algorithms for Intelligent Systems [Internet]. Singapore: Springer; 2020. p. 33–56. Available from: http://link.springer.com/10.1007/978-981-15-1216-2_2.
|
| 6. |
Harrison PJ. The neuropathological effects of antipsychotic drugs. Schizophr Res [Internet]. 1999;40(2):87–99. Available from: https://linkinghub.elsevier.com/retrieve/pii/S0920996499000651.
|
| 7. |
Hepsomali P, Groeger JA, Nishihira J, Scholey A. Effects of Oral Gamma-Aminobutyric Acid (GABA) Administration on Stress and Sleep in Humans: A Systematic Review. Front Neurosci [Internet]. 2020;14. Available from: https://www.frontiersin.org/article/10.3389/fnins.2020.00923/full.
|
| 8. |
Hunkeler W, Möhler H, Pieri L, Polc P, Bonetti EP, Cumin R, et al. Selective antagonists of benzodiazepines. Nature [Internet]. 1981;290(5806):514–6. Available from: https://www.nature.com/articles/290514a0.
|
| 9. |
Hutto C, Gilbert E. VADER: A Parsimonious Rule-Based Model for Sentiment Analysis of Social Media Text. Proc Int AAAI Conf Web Soc Media [Internet]. 2014;8(1):216–25. Available from: https://ojs.aaai.org/index.php/ICWSM/article/view/14550.
|
| 10. |
Kinnersley AM, Turano FJ. Gamma Aminobutyric Acid (GABA) and Plant Responses to Stress. CRC Crit Rev Plant Sci [Internet]. 2000;19(6):479–509. Available from: https://www.tandfonline.com/doi/full/10.1080/07352680091139277.
|
| 11. |
Namerow LB, Thomas P, Bostic JQ, Prince J, Mounteaux MC. Use of Citalopram in Pervasive Developmental Disorders. J Dev Behav Pediatr [Internet]. 2003;24(2). Available from: https://journals.lww.com/jrnldbp/fulltext/2003/04000/use_of_citalopram_in_pervasive_developmental.5.aspx.
|
| 12. |
Ulrich S. Comment on: “Monoamine Oxidase Inhibitors (MAOIs) in Psychiatric Practice: How to Use them Safely and Effectively”. CNS Drugs [Internet]. 2022;36(1):101–2. Available from: https://link.springer.com/10.1007/s40263-021-00881-2.
|
| 13. |
Fedotova J, Kubatka P, Büsselberg D, Shleikin AG, Caprnda M, Dragasek J, et al. Therapeutical strategies for anxiety and anxiety-like disorders using plant-derived natural compounds and plant extracts. Biomed Pharmacother [Internet]. 2017;95:437–46. Available from: https://linkinghub.elsevier.com/retrieve/pii/S0753332217326380.
|
| 14. |
Constable PA, Al-Dasooqi D, Bruce R, Prem-Senthil M. A Review of Ocular Complications Associated with Medications Used for Anxiety, Depression, and Stress. Clin Optom [Internet]. 2022;Volume 14:13–25. Available from: https://www.dovepress.com/a-review-of-ocular-complications-associated-with-medications-used-for--peer-reviewed-fulltext-article-OPTO.
|
| 15. |
Schober P, Boer C, Schwarte LA. Correlation Coefficients: Appropriate Use and Interpretation. Anesth Analg [Internet]. 2018;126(5):1763–8. Available from: https://journals.lww.com/00000539-201805000-00050.
|
| 16. |
Hale AS. Citalopram is safe. BMJ [Internet]. 1998;316(7147):1825–1825. Available from: https://www.bmj.com/lookup/doi/10.1136/bmj.316.7147.1825.
|
| 17. |
McLean MJ. Gabapentin. Epilepsia [Internet]. 1995;36(s2). Available from: https://onlinelibrary.wiley.com/doi/10.1111/j.1528-1157.1995.tb06001.x.
|
| 18. |
Taylor CP. Mechanisms of action of gabapentin. Rev Neurol (Paris) [Internet]. 1997;153 Suppl:S39-45. Available from: http://www.ncbi.nlm.nih.gov/pubmed/9686247.
|
| 19. |
Sanh V, Debut L, Chaumond J, Wolf T. DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter. arXiv Prepr arXiv191001108 [Internet]. 2019; Available from: https://arxiv.org/abs/1910.01108.
|
| 20. |
Wolf T, Debut L, Sanh V, Chaumond J, Delangue C, Moi A, et al. Huggingface’s transformers: State-of-the-art natural language processing; 2019. Available from http://https://arxiv.org/abs/1910.03771
|
